

В этой статье говорится об особенностях параллельных вычислений во FlowVision. Это необходимо знать, чтобы понимать, как получить максимально возможное ускорение от нескольких ядер или процессоров.
Вы узнаете:
- Почему нельзя бесконечно ускорять расчет имея очень много процессоров
- Как ускорение зависит от числа расчетных ячеек
- Как сделать расчет быстрее
- И даже какое "железо" стоит предпочитать для параллельных CFD расчетов
Подробности ниже
Как происходит распараллеливание. Декомпозиция расчетной сетки
Решатель FlowVision начинает свою работу с построения расчетной сетки. В случае параллельных вычислений расчетная сетка в процессе построения делится на несколько частей. После этого FlowVision распределит эти части между процессорами. Ниже приведен пример разбиения расчетной сетки между четырьмя процессорами:
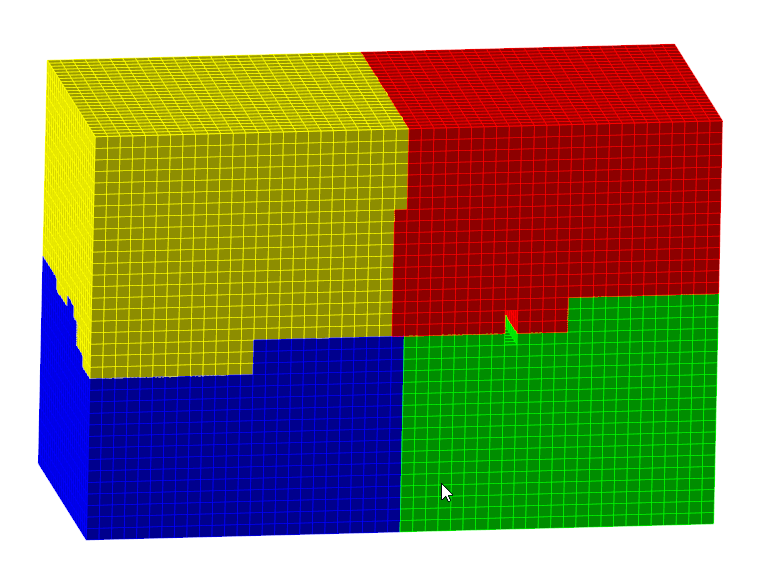
На каждом процессоре будет запущена копия Солвера. Каждая копия будет обсчитывать свою часть расчетной сетки.
Почему нельзя ускорять бесконечно. Обмен данными между процессорами
Но когда каждый Солвер будет считать потоки (тепла, массы) между ячейками, ему понадобятся данные из соседних ячеек. А часть ячеек обсчитываются на соседнем процессоре. Соответственно придется обращаться по сети за данными с удаленной оперативной памяти.
Но такой запрос данных с другого процессора (чужой оперативной памяти) является гораздо более медленным, чем запрос данных из родной оперативной памяти. И чем больше таких обращений, тем больше простоев процессора.
Если мы хотим минимизировать обмены, то необходимо минимизировать площадь границы между частями, розданными между прцоессоров. Этим занимаются специальные алгоритмы во FlowVision, стараясь построить оптимальную декомпозицию.
Из выше сказанно можно сделать важный вывод! Для одинакового числа ячеек имеется следующий эффект: чем больше используется процессоров, тем больше потерь процессорного времени на обмен. Возможна такая ситуация, когда время, затрачиваемая на расчет на процессоре становится меньше времени обмена. В этот момент расчет не только не ускоряется, но и начинает замедляться с ростом числа процессоров. Этот эффект можно заметить на следующей картинке:
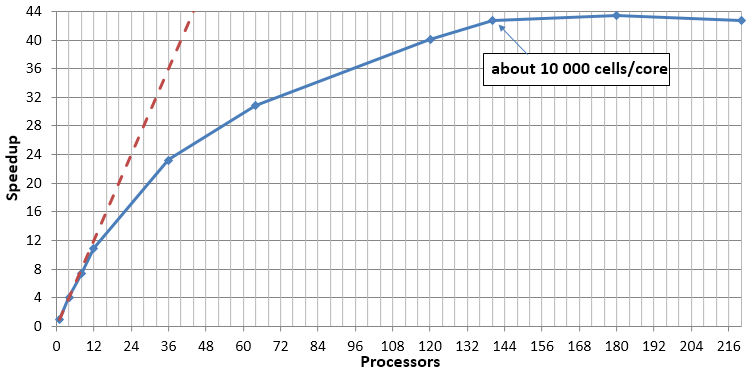
После 180 процессоров начинается замедление, вместо ускорения.
Таким образом важно помнить, что чем меньше ячеек приходится на процессор, тем больше потери (при условии одинакового суммарного числа расчетных ячеек). Обычно оптимальным числом ячеек на ядро (не процессор) - это 10 000 - 40 000 ячеек. При попытке использовать меньшее число ячеек можно получить замедление расчета. Вот так использование меньшего числа процессоров может быть быстрее, чем использование большего.
Что такое масштабируемость?
График, который показан выше - это иллюстрация понятия масштабируемости. Масштабируемость показывает, как увеличение числа процессоров (или ядер) ускоряет расчет. Масштабируемость - это характеристика не только CFD кода, но и "железа" и даже самой расчетной модели. Масштабируемость зависит также от расчетной сетки.
Идеальная масштабируемость - это прямая: когда увеличение числа процессоров в 100 раз дает ускорение в 100 раз. К сожалени, из-за потерь на обмен, это не достижимо.
Локальная адаптация и масштабируемость
Масштабируемость зависит от многих факторов. В частности от того, каким образом построена расчетная сетка. Например, один и тот же проект на одном и том же числе процессоров с 3 миллионами ячейками может считаться быстрее, чем с двумя.
На картинке ниже показан результат локальной адаптации (второй уровень адаптации в объеме). Хорошо видно, что "желтому" процессору досталось больше всего расчетных ячеек. Это значит, что желтый процессор будет считать и считать, в то время как недогруженные красный, синий и зеленый процессоры будут простаивать в ожидании посчитанных желтым процессором данных. Это иллюстрация дисбаланса в распределении расчетной сетки по процессорам, дисбаланса вычислений.
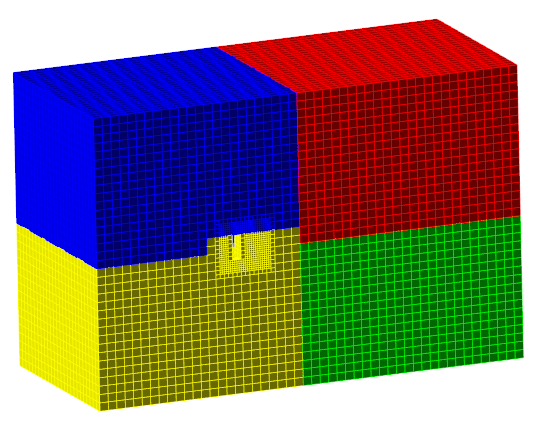
Алгоритмы FlowVision стараются перераспределять сетку так, чтобы восстановить баланс, однако это невсегда возможно.
Перечислю обстоятельства, которые приводят к серьезному дисбалансу:
- Уровень локальной адаптации 4 и выше
- Количество начальных ячеек слишком мало относительно количества расчетных ячеек
- Существует множество ячеек, которые являются нерасчетными (ваккумные, ячейки внутри подвижных тел)
Дисбаланс в таком случае может быть частично или полностью устранен включением Динамической балансировки (настройка во вкладке Солвер).
Старайтесь не использовать локальные адаптации, которые генерируют практически всю расчетную сетку. Использование мелкой начальной сетки может привести к росту числа ячеек, но для параллельных вычислений это может оказаться более эффективным решением, чем экономия одного-двух миллионов.
Узкое горлышко параллельных вычислений. Как железо влияет на масштабируемость
Обмен данными между процессорами (и ядрами тоже!) происходит через оперативную память. Каждый вычислительный поток на каждом ядре обращается за данными в RAM для новой порции вычислений. Все ядра одного процессора обращаются к памяти через одну шину памяти.
Если количество ядер слишком велико, наблюдается эффект бутылочного горлышка:
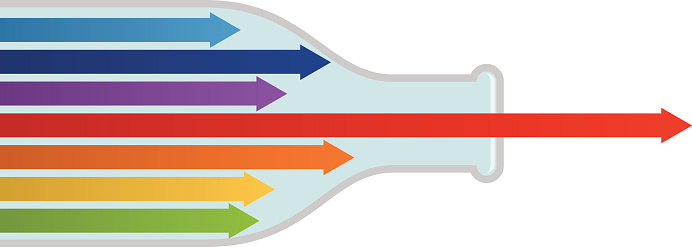
(нажмите на картинку, если нет анимации)
Именно по этой причине параметры оперативной памяти даже важнее характеристик процессора с точки зрения вычислительной гидродинамики. Когда будете выбирать железо под гидродинамические расчеты, выбирайте память с большой частотой и большим числом каналов.
Эффект бутылочного горлышка также обясняет следующее интересное явление: расчет с использованием 80% ядер процессора может быть быстрее, чем расчет с использованием 100% ядер процессора!
О Гипертрейдинге
Hyper-threading (HT) - это технология, которая виртуально увеличивает число физических ядер. Каждое дополнительное логическое ядро позволит использовать вычислительные ресурсы, если вдру произошла пауза (ядро ожидает данные). Эта технология в некоторых случаях позволяет повысить производительность до 30%. Обычно ускорение от гипертрейдинга наблюдается для малого числа процессоров (для задаче с малым числом ячеек), т.е. для вычислений на персональном компьютере. В рамках инженерных многопроцессорных вычсилительных систем как правило гипертрейдинг отключают, т.к. увеличение числа ядер повышает потери на обмены.speedup2
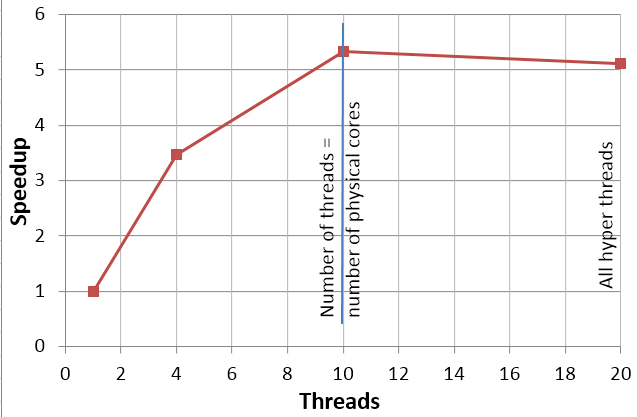
5,2 миллионов ячеек, 8 процессоров
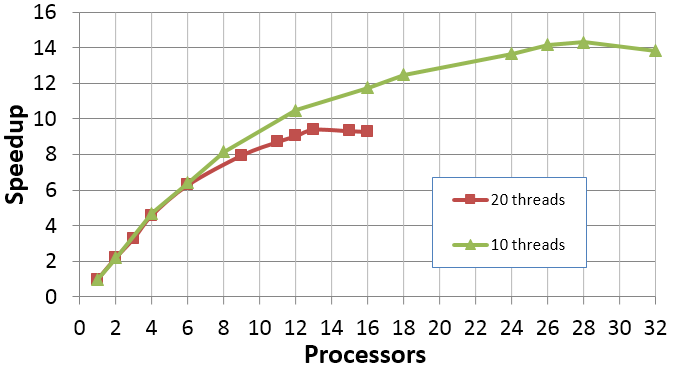
Во многих случаях стоит протестировать, дает ли гипертрейдинг преимущества на конкретном оборудовании для конкретной задачи или нет.
Коротко
когда вы запускаете Солвер в многопроцессорном режиме, проверьте следующее:
- Оптимальное количество ячеек на ядро составляет около 10 000 - 40 000. Больше можно, меньше нельзя.
- Старайтесь использовать адаптацию с уровнем не выше 3 или 4. Если нужно измельчить сетку сильнее, измельчите начальную сетку. Используйте неравномерную сетку, которую можно построить с помощью редактора начальной сетки.
- Если исопльзуете локальную адаптацию высокого уровня, если расчет содержит свободную поверхность между жидкостью и вакуумом, если имеется адаптация высокого уровня по поверхности подвижного тела, используйте Динамическую балансировку
Дополнительные ссылки
- Доступно о параллельных вычислениях
- Использование офисной компьютерной сети для нераспределенных вычислений
- От разработчиков и пользователей FlowVision
- Исследование масштабируемости вычислений в ПК FlowVision на суперкомпьютере "Ломоносов" и "Ломоносов-2"
- Использование инструментов Intel в разработке программного комплекса FlowVision
- Исследование эффективности распараллеливания расчета движения подвижных тел и свободных поверхностей на компьютерах с распределенной памятью
- Распараллеливание вычислений с поверхностными межпроцессорными границами, масштабируемость
- Решение больших задач вычислительной гидродинамики на СКИФ МГУ с помощью FlowVision